원티드 프리온보딩 인턴십 교육 (11차) 사전과제 주제는 투두리스트 만들기였습니다. 간단한 투두리스트 라고 생각할 수 있지만, 뭐든지 간단한만큼 신경쓸게 더 많다는 사실.. 방심하지 않고 핵심 기능들을 최대한 깔끔하게 구현해보자 라는 생각으로 임해보았습니다.
여담이지만 .. 왜 저는 항상 팀장이 되는걸까요 ..? 흑..
사전 개인과제 요구사항
기능구현에 직접적으로 연관된 라이브러리 사용은 허용되지 않습니다.(React-Query 등)
README.md 작성은 필수입니다. 아래의 사항은 반드시 포함되도록 해주세요
페이지별로 요구되는 경로는 도메인 URL뒤에 바로 이어지도록 설정해주세요
기본적으로 진입 루트가 회원가입 -> 로그인 -> 투두리스트 였고, 기능 구현에 연관된 라이브러리는 사용하지 않는것이 기본 규칙이었습니다.
1주차 팀 과제 요구사항
팀빌딩이 이뤄지고 진행되는 1주차 팀 과제는BestPractice를 선정하여 사전과제를 리팩토링 하는것이었습니다.
Best Practice란 모범사례라는 말로서, 특정 문제를 효과적으로 해결하기 위한 가장 성공적인 해결책 또는 방법론을 의미합니다.
쉽게말해사전과제의 핵심 기능을 파트별로 나눠, 가장 잘 작성된 코드를 선정해 선정된것들로만 이뤄진 프로젝트를 완성해 제출하는 것이 1주차 과제였습니다.
1주차 세션에서 진행했던 협업을 위한 툴들을 적용시키기 위해ES Lint 와 Prettier, 그리고 husky를 사용하여 포멧팅을 자동화 하도록 진행했고,
너무 세분화하여 진행하지 않고 큰 부분들만 나눠서 불필요한 딜레이를 줄이는것을 목표로 진행되었기 때문에고민사항은 크게 3가지로 분류하여 BestPractice 를 선정했습니다. (진행은 팀별 디스코드 채널,노션을 생성해 회의와 회의내용을 정리하여 기록하며 진행했습니다.)
파일트리
전체적으로 팀원들이프로젝트의 디테일한 폴더 구조에 대한 고민이 많았기 때문에여러부분을 참고하여 진행했지만실무를 겪어보지 못했기 때문에 프로젝트의 규모별로 괜찮은 파일트리를 선정하기 어려웠다는 의견들이 많았습니다.
인증/인가 로직
인증에 대한 로직을어디서구현해야 할지, 공통 로직을분리할 수 있을지, 그리고 그것을어떻게구현해야 할지에 대한 고민이 많았습니다.
컴포넌트 분리
컴포넌트를 어떻게어떠한 기준으로 분리하여 유지보수에 최적화된 컴포넌트를 구현할 수 있을지에 대한 고민이 공통적으로 존재했습니다.
과제 진행중 고민되었던 부분
개인 : 파일트리
개인으로 진행했던 사전과제의 경우에는 파일트리를 프로젝트 전체 깊이가 깊어지더라도 세분화하여 폴더를 생성하여 각 폴더별로 메인이 될 수 있는 컴포넌트를 index.tsx 로 생성하여 관리하는 구조를 택했습니다.
해당 구조가 개인적으로 각각의 컴포넌트에 대한 작명만 잘한다면 도서관의 원하는 도서 찾기처럼 크게 불편함이 없는 상태로 세분화를 할 수 있겠다는 생각이 들었습니다.
이전에 진행했던 개인 프로젝트는 아무래도 하나하나를 세분화 하다보니 전체적으로 깊이가 너무 깊어져서 오히려 가독성을 더욱 해칠 수 있겠다는 생각이 들었기 때문에이번 프로젝트는 진행하면서 자식 컴포넌트 (HeaderMenu 의 Menu 같은)는 따로 폴더를 생성하지 않고 해당 컴포넌트의 이름으로 네이밍을 하는 방식으로 진행하였습니다.
팀 : 파일트리
팀과제로 진행된 프로젝트의 경우에는 일단 컴포넌트 구현에 앞서서 정확한 파일트리와 인증로직 구현을 진행 후에 컴포넌트를 구현하는게 맞다고 생각했기 때문에 파일트리를 먼저 정하게 되었습니다.
전체적으로 저는 백엔드를 학습하다가 프론트엔드를 시작했었던지라, 백엔드 프로젝트를 진행할 땐 항상 확장에 대한 가능성을 열어둔 채로 프로젝트를 진행했기 때문에 최대한 쪼갤 수 있는 부분은 쪼개고 각각의 모듈에 대해서 관심사를 분리하는것을 메인으로 삼고 진행했으나,
공통적으로 프론트엔드 개발자분들은 대부분 현재 진행하는 프로젝트의 규모에 따라 방식을 정하는듯 하셨습니다.
저희 팀의 경우 현재 진행해야 하는 투두리스트 또한 규모 자체가 크지 않았기 때문에과한 세분화는 지양하고 최대한 커뮤니케이션에 문제가 없게끔 파일트리를 정의하여 깔끔한 프로젝트를 진행하기로 결정되었습니다.
여기에 api로직에 대한 부분들은 저의 방식을 BestPractice 로 선정해 apis 폴더에 각 컴포넌트 별로 비즈니스로직을 분리하여 선언하도록 구현했습니다.
해당 부분에 있어서는기본적으로 큰 부분 (컴포넌트들,api들, 페이지들 등) 으로 나누어 폴더를 생성 후 각 부분에 맞춰서 필요시에 폴더를 생성하고, 큰 이유가 없다면 파일만 생성하여 관리하는 구조를 택했고,전체적으로 파일 트리는 아래와 같이 정의되었습니다.
팀 진행으로 인해 얻어간것들 (파일트리)
어떻게 보면 제가 개인으로 정의했던 파일트리는 예를 들었을 때 쓸데없이 즉섭밥을 데워먹어야하는 상황임에도 직접 지은 밥을 고수하는 듯한 느낌을 줄 수도 있겠구나 .. 라는 생각을 하게 되었습니다.
다른분들의 의견을 통해 상황별로 해당 구조가 필요한 경우가 있겠지만 너무 과하게 멀리보고 진행하기보다는 확실한 규모를 정하고 프로젝트를 진행하는게 좋겠다는 생각을 다시 한번 하게 되었습니다.개발은 아무래도 나 혼자 하는것이 아니기 때문에 ..
개인 : 인증 로직 구현
인증 로직의 경우에는 기본적으로요청시에 헤더에 토큰을 포함시키고, 토큰이 만료되거나 비밀번호가 옳지 않을때는 공통적으로 401에러를 반환하기 때문에axios interceptor 로 분리하여 로직을 구현할 수 있겠다는 생각이 들었습니다.
이에 대해서 들었던 생각은 두가지였습니다.
ContextAPI 를 사용하여 인증 상태값 저장하기
단순히 LocalStorage 에서 토큰값을 가져와서 헤더에 포함시키기
이번 과제의 경우에는메인 기능을 구현하는데에 있어서 관련된 라이브러리를 설치하여 사용하는것이 금지되었기 때문에ContextAPI 를 사용하여 구현하는것을 생각했습니다.
하지만 Axios Interceptor 의 경우에는 해당 로직 내부에서 hook사용이 불가능했기 때문에 구현에 있어서 문제가 발생했습니다.
따라서Axios Interceptor 에서는 매 요청시마다 로컬스토리지에 저장된 값을 확인이 가능했기 때문에 로컬스토리지에서 토큰을 찾아서 같이 포함시켰고, Context API는 인증 여부에 따른 라우팅을 담당하는데에 사용하였습니다.
단순히 라우팅시에도 localStorage 에서 값을 찾아오면, 해당 변수에 저장된 boolean 값이 계속 업데이트 되는것이 아니기때문에 제대로된 구현이 어려웠습니다. +@ 로 useEffect를 사용하여 navigate시에는 블링크 현상이 발생했기 때문에 신경쓸 부분이 많았습니다. (예: 토큰이 없는 상황에서 Todo로 라우팅시에 SignIn 컴포넌트로 네비게이트)
하나의 기능에 대한 구현을 여러 방법으로 구현하는것 처럼 보일 수 있었지만, 이렇게 지속적으로 인증 상태가 변경되는 부분을 감시해야하는 상황에서는 Context API 를 사용했고, Interceptor 에서는 LocalStorage 의 토큰 유무를 매 요청마다 확인하여 반영할 수 있었기 때문에 단순히 getItem 으로 유무를 확인 후 포함하도록 구현했습니다.
투두리스트를 구현하면서 가장 고민되었던 컴포넌트 분리 부분은 아무래도 요구사항 중투두를 수정할 때 기존의 text가 사라지면서 input 으로 변경 된 후 '수정', '삭제' 버튼 또한 '제출','취소' 버튼으로 변경이 되도록 구현하는 것이었는데,
해당 부분을 수정모드일때의 컴포넌트를 구현하여 반영을 할지, 혹은 하나의 컴포넌트에 반영을 할지 고민이 많이 되었고, 주변의 어느분께 헬프를 요청하여 아이디어를 얻게 되었습니다.
아무래도 현업에서 개발을 하고 계시는 프론트엔드 개발자 분들도 공통적으로 고민하는 부분이 컴포넌트 분리에 대한 고민이라고 하시면서, 본인은 각 컴포넌트를 역할별로 분리한다고 하셨고,해당 투두에대한 수정과 삭제는 해당 투두(항목) 밖에선 일어날 일이 없으므로 굳이 분리할 필요가 없다고 하셨고, 해당 의견을 참고하여 구현하였습니다.
기본적으로 큰 페이지는 투두 입력창 / .map() 을 활용한 투두 로 구성이 되도록 하였으며 투두컨텐츠라는 컴포넌트에 수정/삭제 로직을 포함시켜 구현하였습니다.
TodoInput 또한 마찬가지로 useFormControl 훅을 재사용해 핵심 로직을 분리시켜서 가독성에 신경썼습니다.
TodoContent 는 과제 명세에 포함된 내용을 참고하여디테일한 부분을 살리려 노력했습니다.(수정중에 체크박스를 클릭해도 업데이트가 진행된다던지 하는 부분들)
저같은 경우에는 팀원 중 기본적으로 구현이 되어야하는 컴포넌트 (예 : input, button 등) 을 먼저 구현 후 각 큰 컴포넌트 별로 다시 스타일링 및 구현을 진행한 후 페이지를 완성한 팀원분의 코드를 보고 구조적으로 깔끔하다 생각되어 해당 팀원분을 선정하였습니다.
스타일링 또한 기본적으로 코딩 컨벤션을 지켜가면서 기능 / 스타일링을 철저히 분리해 가독성을 살리셨고, 다른 팀원분들 또한 마찬가지로 의견이 거의 동일하게 해당 팀원분을 선정하여 진행됐습니다.
여기서 제가 진행했던 부분은 TodoInput 을 구현하는 것이었는데, 구현하는김에 제가 개인적으로 구현했던 useFormControl 훅을 재사용해 useInput 이라는 커스텀 훅을 구현했고,
해당 훅을 구현시에 고민했던 부분 (불필요한 리턴값에 대한 핸들링) 을 반영하여배열 타입으로 반환하지 않고 객체 타입으로 반환하도록 구현했습니다.
여기에 BestPractice 로 선정된 팀원분의 의견 (현업에선 UI/UX디자이너 분들께서 MUI , Chakra같은 스타일링 라이브러리를 사용하는것을 안좋아한다)을 참고하여 직접 common 컴포넌트를 구성해 구현하도록 했기때문에, Input 컴포넌트를 직접 구현하게 되었습니다.
interface IUseInputReturn<T> {
onChange: React.ChangeEventHandler<HTMLInputElement>;
value: T;
setValue: React.Dispatch<React.SetStateAction<T>>;
isValidated: boolean;
setIsValidated: React.Dispatch<React.SetStateAction<boolean>>;
setFocus: () => void;
setBlur: () => void;
}
const useInput = <T>(options: {
regex?: RegExp;
ref?: RefObject<HTMLInputElement>;
initialValue?: T;
}): IUseInputReturn<T> => {
const { regex } = options || {};
const [value, setValue] = useState<T>((options.initialValue as T) ?? ('' as unknown as T));
const [isValidated, setIsValidated] = useState<boolean>(false);
const validateValue = (value: T) => {
if (typeof value === 'string' && regex) {
const isValid = regex.test(value);
setIsValidated(isValid);
} else {
setIsValidated(false);
}
};
const setFocus = () => {
if (options.ref) {
options.ref.current?.focus();
}
};
const setBlur = () => {
if (options.ref) {
options.ref.current?.blur();
}
};
const onChange: React.ChangeEventHandler<HTMLInputElement> = (e) => {
const newValue = e.target.value as unknown as T;
if (newValue !== value) {
setValue(newValue);
validateValue(newValue);
}
};
// 기본적으로 훅 사용할때 <type> 형식으로 타입 지정 해주시거나 (객체도 가능) 초기화값 지정해주시면 타입 자동으로 들어갈겁니다.
/* 폼 제출시 유효성 검사 초기화, 값 초기화를 위해 setter 까지 반환하도록 했습니다.
전체적으로 빈 값이 들어가는 경우는 없기때문에 정규표현식으로 관리하도록 구현했습니다.*/
/* const { data: data1, isLoading: isLoading1 } = useCustomHook(params1);
const { data: data2, isLoading: isLoading2 } = useCustomHook(params2);*/
/* 여러번 선언해야할 경우 위와 같이 사용하면 됩니다. (여러번 사용하지 않더라도 변수명 헷갈리지 않게 하기 위해 이렇게 사용하시는걸 추천드립니다.) */
return { onChange, value, setValue, isValidated, setIsValidated, setFocus, setBlur };
};
export default useInput;
개인과제로 진행했던 hook은 아무 생각 없이 단순 string 만을 핸들링하도록 구현했고, 이를 반성하며 리팩토링을 통해 제네릭 타입으로 checkbox 등에도 사용할 수 있도록 변경하였습니다. 여기에 refObject 를 전달받아서 focus나 blur 같은 이벤트도 구현할 수 있도록 전체적으로 react-hook-form 의 기능을 모방하여 사용할 수 있도록 구현하였습니다.
input 의 경우에는 기본적으로 input 태그가 갖고있는 attribute를 다 받아올 수 있도록 인터페이스 선언 시에 HTMLProps를 상속받아 사용하도록 구현했고, ref 같은 경우에는 따로 전달하는 값이 있기때문에 Omit 을 사용하여 해당 인터페이스중 ref 항목을 제외하고 상속받도록 구현했습니다.
팀 진행으로 인해 얻어간 것들 (컴포넌트 분리)
Omit과 HTMLProps 라는 새로운 것을 알게되었습니다.
common component 를 구현할 때 쓸데없이 interface 에 property를 와바박 쓸 일이 없어졌습니다..
아무래도 컴포넌트 구현을 저 혼자 하는게 아니었기 때문에 협업을 통해 리팩토링에 신경쓰게 되었고, useInput 을 구현할 때 제네릭 타입을 처음 사용하는 등의 경험이 소중하게 느껴졌습니다.
마찬가지로 주석처리에 신경쓰게 되었고, 커뮤니케이션의 대부분이 컴포넌트 구현 파트에서 이뤄졌기 때문에 실무를 정말 간접적으로 경험할 수 있었습니다.
오히려 좋았던점은 커스텀훅을 사용하는 법이 익숙치 않았던 팀원분께서 계셨고, 이로 인해서 주석처리나 가독성 좋은 코드를 작성하려 많이 노력했던 부분이 오히려 실력상승으로 이어지게 되었습니다.
개인 : 테스팅
이번 과제에는 존재하지 않았지만, 개인적으로 Jest를 이용한 테스트코드 작성에 대한 흐름이 매번 궁금했었고,전체적으로 프로젝트 규모가 크지 않으니 이번 기회에 배워서 작성해볼 수 있겠다 !라는 생각을 갖고 테스트코드 작성을 시도해보았습니다.
테스트는 기본적으로 각 Page별로 진행했고, 상황별로 mocking 을 통해 api를 호출했을때의 상황, routing 유무 등을 테스트하였습니다.
Test Suites: 3 passed, 3 total
Tests: 28 passed, 28 total
Snapshots: 3 passed, 3 total
Time: 4.639 s
Ran all test suites related to changed files.
이런식으로 총 28개의 단위테스트를 3개의 페이지별로 진행했고, 모두 통과하였습니다. 다행히 스프링부트로 개발을 하면서 단위테스트를 진행했던 경험이 있어서 테스팅 라이브러리를 익히는데에 큰 문제는 없었으나
어려웠던건 스프링부트때와 똑같이 mocking 에 대한 부분이었습니다. 스프링부트는내가 직접 생성하고 작성한 클래스나 api들을 mocking 해서 단위 테스트를 진행했으나,jest를 이용할때에는내가 직접 작성한 비즈니스 로직 외에도 npm 으로 설치한 라이브러리까지 mocking 하여 상황별로 given 을 지정해야했기 때문에 ..적응하는데 시간이 꽤 걸렸습니다.
아무래도 해당 부분은 리액트의 동작원리를 파악한다면 더 쉽게 이해할 수 있지 않았을까 하는 생각이 들었습니다.
좋았던점과 아쉬웠던점
좋았던점
프론트엔드로 팀 개발에 참여한게 처음이었지만 전체적으로 능동적으로 행동하시는 팀원분들과 함께해서좋은 첫 스타트를 함께 할 수 있었습니다.
개발 공부를 시작한 이후로, 어디를 가던 팀장 역할을 맡아가면서 매번 저의 자질에 대한 고민을 항상 해왔는데,이번을 계기로 확실히 나는 묻어가는거도 잘하지만 이끄는거도 나쁘지 않게 하고 있구나 라는 생각을 하게 되었습니다.
팀원의 장단점을 잘 파악해 역할 분담을 적절하게 잘한것같습니다.
팀장이라고 무조건 저의 방식대로 강압적으로 리드하지 않고 중립을 지켜가면서 전체적으로 어느 한 분위기에 휩쓸려서 진행되지 않도록 잘 진행한것 같습니다.
전체적으로 실력향상을 할 수 있게끔 핸들링을 한 것 같습니다.
다른 팀원분들께서 어려움을 겪는 부분이 있으실 때 최대한 할 수 있는 부분까지 진행하도록 격려하고 나머지 부분은 제가 도와드리는 방식으로 진행했기 때문에, (라이브코딩) 여러모로 상대방이나 제 자신한테 도움되는 부분이 많았다고 생각했습니다.
아쉬웠던점
최악의 상황에 대한 대비책을 준비해두지 못했던게 아쉬웠습니다.
이번 프로젝트의 경우에는 사상 최초로 잠수를 타는 팀원이 존재했고, 그 팀원을 믿고 해당 파트에 대한 대비책을 준비해두지 않았던 부분이 굉장히 아쉬웠습니다.
그 팀원으로 인해 전체적인 스타일링이 기본 컴포넌트를 구현해 스타일링까지 직접 진행하는걸로 결정되었었지만, 해당 팀원이 제출 당일 저녁시간부터 연락이 되지 않아 급하게 마무리하여 제출하게 되었습니다.
해당 팀원을 탓할수도 있지만,팀장으로써 미리 대비책을 준비해두지 않았던게 굉장히 아쉬웠습니다.프로페셔널한 개발자라면 미리 이러한 상황에 대비하여 진행해야 했다는 생각이 들었습니다.
하지만 이로 인해서 다음 과제부터는불필요한 시간 투자를 줄이고 최대한 해당 과제의 규모에 맞춰서 라이브러리를 선정하여 진행해야겠다는 생각을 하게 되었습니다.
마치며
처음으로 합류해봤던 프론트엔드 교육이라 떨리는 마음으로 임하고 있지만, 1주차 과제를 어찌저찌 끝내고 드는 생각은 아무래도 '시간이 지나고 보면 다 별거 아닌 일들이다' 인 것 같습니다.
2주차 과제는 1주차 과제에서 미흡했던 점, 아쉬웠던 점을 보완하여 욕심 부리지 않고 깔끔하게 마무리 하는 방향으로 가려고 합니다.
오랜만에 작성하는 회고록인만큼 열심히 깔끔하게 작성하려 노력했는데 잘 모르겠네요.. 읽어주셔서 감사합니다!
신입사원 무지는 게시판 불량 이용자를 신고하고 처리 결과를 메일로 발송하는 시스템을 개발하려 합니다. 무지가 개발하려는 시스템은 다음과 같습니다.
각 유저는 한 번에 한 명의 유저를 신고할 수 있습니다.
신고 횟수에 제한은 없습니다. 서로 다른 유저를 계속해서 신고할 수 있습니다.
한 유저를 여러 번 신고할 수도 있지만, 동일한 유저에 대한 신고 횟수는 1회로 처리됩니다.
k번 이상 신고된 유저는 게시판 이용이 정지되며, 해당 유저를 신고한 모든 유저에게 정지 사실을 메일로 발송합니다.
유저가 신고한 모든 내용을 취합하여 마지막에 한꺼번에 게시판 이용 정지를 시키면서 정지 메일을 발송합니다.
다음은 전체 유저 목록이 ["muzi", "frodo", "apeach", "neo"]이고, k = 2(즉, 2번 이상 신고당하면 이용 정지)인 경우의 예시입니다.
유저 ID 유저가 신고한 ID 설명
"muzi"
"frodo"
"muzi"가 "frodo"를 신고했습니다.
"apeach"
"frodo"
"apeach"가 "frodo"를 신고했습니다.
"frodo"
"neo"
"frodo"가 "neo"를 신고했습니다.
"muzi"
"neo"
"muzi"가 "neo"를 신고했습니다.
"apeach"
"muzi"
"apeach"가 "muzi"를 신고했습니다.
각 유저별로 신고당한 횟수는 다음과 같습니다.
유저 ID 신고당한 횟수
"muzi"
1
"frodo"
2
"apeach"
0
"neo"
2
위 예시에서는 2번 이상 신고당한 "frodo"와 "neo"의 게시판 이용이 정지됩니다. 이때, 각 유저별로 신고한 아이디와 정지된 아이디를 정리하면 다음과 같습니다.
유저 ID 유저가 신고한 ID 정지된 ID
"muzi"
["frodo", "neo"]
["frodo", "neo"]
"frodo"
["neo"]
["neo"]
"apeach"
["muzi", "frodo"]
["frodo"]
"neo"
없음
없음
따라서 "muzi"는 처리 결과 메일을 2회, "frodo"와 "apeach"는 각각 처리 결과 메일을 1회 받게 됩니다.
이용자의 ID가 담긴 문자열 배열 id_list, 각 이용자가 신고한 이용자의 ID 정보가 담긴 문자열 배열 report, 정지 기준이 되는 신고 횟수 k가 매개변수로 주어질 때, 각 유저별로 처리 결과 메일을 받은 횟수를 배열에 담아 return 하도록 solution 함수를 완성해주세요.
제한사항
2 ≤ id_list의 길이 ≤ 1,000
1 ≤ id_list의 원소 길이 ≤ 10
id_list의 원소는 이용자의 id를 나타내는 문자열이며 알파벳 소문자로만 이루어져 있습니다.
id_list에는 같은 아이디가 중복해서 들어있지 않습니다.
1 ≤ report의 길이 ≤ 200,000
3 ≤ report의 원소 길이 ≤ 21
report의 원소는 "이용자id 신고한id"형태의 문자열입니다.
예를 들어 "muzi frodo"의 경우 "muzi"가 "frodo"를 신고했다는 의미입니다.
id는 알파벳 소문자로만 이루어져 있습니다.
이용자id와 신고한id는 공백(스페이스)하나로 구분되어 있습니다.
자기 자신을 신고하는 경우는 없습니다.
1 ≤ k ≤ 200, k는 자연수입니다.
return 하는 배열은 id_list에 담긴 id 순서대로 각 유저가 받은 결과 메일 수를 담으면 됩니다.
1차적으로는 해당 회원의 인덱스를 갖고있는 배열이 필요해보였고, 신고 상황을 저장할 배열, 신고 누적 횟수를 저장할 배열, 그리고 이메일 송신 횟수를 갖는 배열 이렇게 4개의 배열을 선언할까 생각했었고,
2차적으로는 인덱스를 해시맵으로 구현, 신고상황은 한 회원이 여러번 같은 회원을 신고할 , 다른 회원을 신고한 기록도 저장해야 하니 해시맵이 아닌 리포트배열은 2차원으로 , 그리고 신고 누적 횟수는 해시맵, 그리고 이메일 배열은 마찬가지로 2차원 배열로 구현하였다 (?)
제출 이후인 3차적으로 생각하면 인덱스와 누적 신고 횟수를 합쳐서 정수 리스트를 같는 해시맵과 신고누적 횟수 해시맵 이렇게 2개만 선언해도 됐을 것 같다.
class Solution {
public List<Integer> solution(String[] id_list, String[] report, int k) {
List<Integer> answer = new ArrayList<>();
HashMap<String,Integer> idxMap = new HashMap<>();
HashMap<String,Integer> reportedMap = new HashMap<>();
int[][] reportArr = new int[id_list.length][id_list.length];
int[][] emailArr = new int[id_list.length][1];
int idx = 0;
for(String id : id_list){
reportedMap.put(id,0);
idxMap.put(id,idx);
for(int j=0; j<id_list.length;j++){
reportArr[idx][j]=0;
}
idx++;
}
for(String detail:report){
int spaceIdx = detail.indexOf(" ");
String reportFrom = detail.substring(0,spaceIdx);
String reportTo = detail.substring(spaceIdx+1,detail.length());
int fromIdx = idxMap.get(reportFrom);
int toIdx = idxMap.get(reportTo);
if(reportArr[toIdx][fromIdx]!=1){
reportArr[toIdx][fromIdx]=1;
reportedMap.put(reportTo,reportedMap.get(reportTo)+1);
}
}
reportedMap.forEach((key,value)->{
if(value>=k){
int toIdx = idxMap.get(key);
for(int i=0; i<id_list.length;i++){
if(reportArr[toIdx][i]==1){
emailArr[i][0]++;
}
}
}
});
for(int i=0; i<id_list.length;i++){
answer.add(emailArr[i][0]);
}
return answer;
}
}
코딩테스트를 준비하는 머쓱이는 프로그래머스에서 문제를 풀고 나중에 다시 코드를 보면서 공부하려고 작성한 코드를 컴퓨터 바탕화면에 아무 위치에나 저장해 둡니다. 저장한 코드가 많아지면서 머쓱이는 본인의 컴퓨터 바탕화면이 너무 지저분하다고 생각했습니다. 프로그래머스에서 작성했던 코드는 그 문제에 가서 다시 볼 수 있기 때문에 저장해 둔 파일들을 전부 삭제하기로 했습니다.
컴퓨터 바탕화면은 각 칸이 정사각형인 격자판입니다. 이때 컴퓨터 바탕화면의 상태를 나타낸 문자열 배열 wallpaper가 주어집니다. 파일들은 바탕화면의 격자칸에 위치하고 바탕화면의 격자점들은 바탕화면의 가장 왼쪽 위를 (0, 0)으로 시작해 (세로 좌표, 가로 좌표)로 표현합니다. 빈칸은 ".", 파일이 있는 칸은 "#"의 값을 가집니다. 드래그를 하면 파일들을 선택할 수 있고, 선택된 파일들을 삭제할 수 있습니다. 머쓱이는 최소한의 이동거리를 갖는 한 번의 드래그로 모든 파일을 선택해서 한 번에 지우려고 하며 드래그로 파일들을 선택하는 방법은 다음과 같습니다.
드래그는 바탕화면의 격자점 S(lux, luy)를 마우스 왼쪽 버튼으로 클릭한 상태로 격자점 E(rdx, rdy)로 이동한 뒤 마우스 왼쪽 버튼을 떼는 행동입니다. 이때, "점 S에서 점 E로 드래그한다"고 표현하고 점 S와 점 E를 각각 드래그의 시작점, 끝점이라고 표현합니다.
점 S(lux, luy)에서 점 E(rdx, rdy)로 드래그를 할 때, "드래그 한 거리"는 |rdx - lux| + |rdy - luy|로 정의합니다.
점 S에서 점 E로 드래그를 하면 바탕화면에서 두 격자점을 각각 왼쪽 위, 오른쪽 아래로 하는 직사각형 내부에 있는 모든 파일이 선택됩니다.
예를 들어
wallpaper
= [".#...", "..#..", "...#."]인 바탕화면을 그림으로 나타내면 다음과 같습니다.
이러한 바탕화면에서 다음 그림과 같이 S(0, 1)에서 E(3, 4)로 드래그하면 세 개의 파일이 모두 선택되므로 드래그 한 거리 (3 - 0) + (4 - 1) = 6을 최솟값으로 모든 파일을 선택 가능합니다.
(0, 0)에서 (3, 5)로 드래그해도 모든 파일을 선택할 수 있지만 이때 드래그 한 거리는 (3 - 0) + (5 - 0) = 8이고 이전의 방법보다 거리가 늘어납니다.
머쓱이의 컴퓨터 바탕화면의 상태를 나타내는 문자열 배열 wallpaper가 매개변수로 주어질 때 바탕화면의 파일들을 한 번에 삭제하기 위해 최소한의 이동거리를 갖는 드래그의 시작점과 끝점을 담은 정수 배열을 return하는 solution 함수를 작성해 주세요. 드래그의 시작점이 (lux, luy), 끝점이 (rdx, rdy)라면 정수 배열 [lux, luy, rdx, rdy]를 return하면 됩니다.
제한사항
1 ≤ wallpaper의 길이 ≤ 50
1 ≤ wallpaper[i]의 길이 ≤ 50
wallpaper의 모든 원소의 길이는 동일합니다.
wallpaper[i][j]는 바탕화면에서 i + 1행 j + 1열에 해당하는 칸의 상태를 나타냅니다.
고객의 약관 동의를 얻어서 수집된 1~n번으로 분류되는 개인정보 n개가 있습니다. 약관 종류는 여러 가지 있으며 각 약관마다 개인정보 보관 유효기간이 정해져 있습니다. 당신은 각 개인정보가 어떤 약관으로 수집됐는지 알고 있습니다. 수집된 개인정보는 유효기간 전까지만 보관 가능하며, 유효기간이 지났다면 반드시 파기해야 합니다.
예를 들어, A라는 약관의 유효기간이 12 달이고, 2021년 1월 5일에 수집된 개인정보가 A약관으로 수집되었다면 해당 개인정보는 2022년 1월 4일까지 보관 가능하며 2022년 1월 5일부터 파기해야 할 개인정보입니다.당신은 오늘 날짜로 파기해야 할 개인정보 번호들을 구하려 합니다.
모든 달은 28일까지 있다고 가정합니다.
다음은 오늘 날짜가 2022.05.19일 때의 예시입니다.
약관 종류 유효기간
A
6 달
B
12 달
C
3 달
번호 개인정보 수집 일자 약관 종류
1
2021.05.02
A
2
2021.07.01
B
3
2022.02.19
C
4
2022.02.20
C
첫 번째 개인정보는 A약관에 의해 2021년 11월 1일까지 보관 가능하며, 유효기간이 지났으므로 파기해야 할 개인정보입니다.
두 번째 개인정보는 B약관에 의해 2022년 6월 28일까지 보관 가능하며, 유효기간이 지나지 않았으므로 아직 보관 가능합니다.
세 번째 개인정보는 C약관에 의해 2022년 5월 18일까지 보관 가능하며, 유효기간이 지났으므로 파기해야 할 개인정보입니다.
네 번째 개인정보는 C약관에 의해 2022년 5월 19일까지 보관 가능하며, 유효기간이 지나지 않았으므로 아직 보관 가능합니다.
따라서 파기해야 할 개인정보 번호는 [1, 3]입니다.
오늘 날짜를 의미하는 문자열 today, 약관의 유효기간을 담은 1차원 문자열 배열 terms와 수집된 개인정보의 정보를 담은 1차원 문자열 배열 privacies가 매개변수로 주어집니다. 이때 파기해야 할 개인정보의 번호를 오름차순으로 1차원 정수 배열에 담아 return 하도록 solution 함수를 완성해 주세요.
제한사항
today는 "YYYY.MM.DD" 형태로 오늘 날짜를 나타냅니다.
1 ≤ terms의 길이 ≤ 20
terms의 원소는 "약관 종류 유효기간" 형태의 약관 종류와 유효기간을 공백 하나로 구분한 문자열입니다.
약관 종류는 A~Z중 알파벳 대문자 하나이며, terms 배열에서 약관 종류는 중복되지 않습니다.
유효기간은 개인정보를 보관할 수 있는 달 수를 나타내는 정수이며, 1 이상 100 이하입니다.
1 ≤ privacies의 길이 ≤ 100
privacies[i]는 i+1번 개인정보의 수집 일자와 약관 종류를 나타냅니다.
privacies의 원소는 "날짜 약관 종류" 형태의 날짜와 약관 종류를 공백 하나로 구분한 문자열입니다.
날짜는 "YYYY.MM.DD" 형태의 개인정보가 수집된 날짜를 나타내며, today 이전의 날짜만 주어집니다.
privacies의 약관 종류는 항상 terms에 나타난 약관 종류만 주어집니다.
today와 privacies에 등장하는 날짜의 YYYY는 연도, MM은 월, DD는 일을 나타내며 점(.) 하나로 구분되어 있습니다.
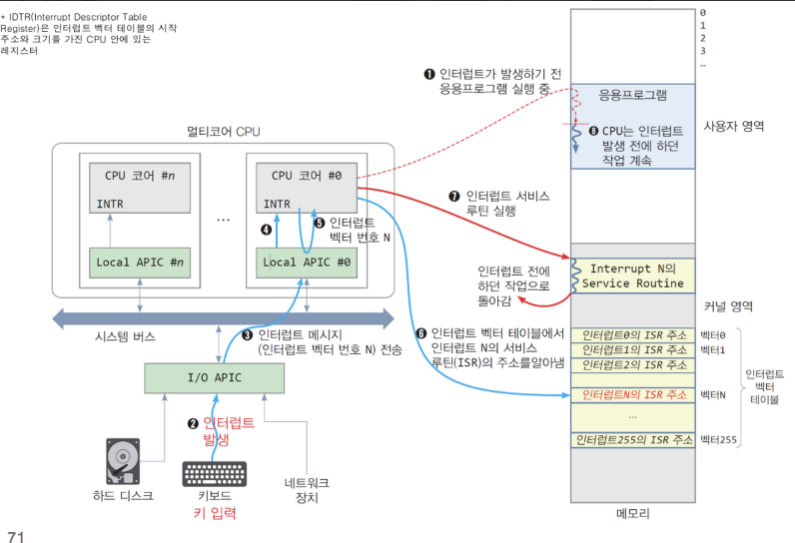
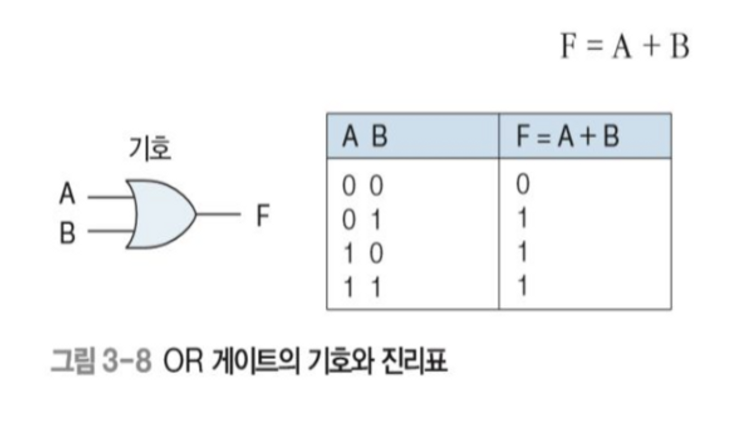
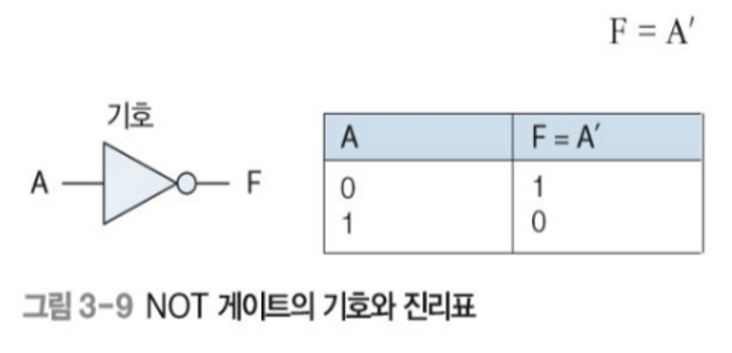
인터럽트 발생 전 프로그램 실행 중 → 입력장치로부터 인터럽트 발생 → 인터럽트 메시지 CPU로 전송 → CPU코어로부터 전송 및 인터럽트 벡트 번호 반환 → 인터럽트 벡터 테이블에서 인터럽트의 서비스 루틴의 주소를 알아낸다. → 인터럽트 서비스 루틴 실행 → CPU는 인터럽트 발생 전에 하던 작업을 지속한다.
인터럽트 서비스 루틴
ISR → 인터럽트 핸들러
위치 : 디바이스 드라이버나 커널 코드, 임베디드 컴퓨터 ROM
인터럽트는 다중 프로그래밍 실현의 키이다.
다중 프로그래밍 리뷰
여러 프로세스를 동시에 실행한다. (멀티 프로그래밍)
프로그래밍과 프로세서는 프로그램 하나가 프로세서 하나를 같이 운영 할 수 있다.
한 프로세스가 입출력을 시행하면 다른 프로세스로 교체 실행된다.
입출력이 완료될 때, 장치로부터 입출력 완료 통보를 받는 방법이 필요하고 그것이 바로 인터럽트이다.
인터럽트가 없다면 ? → CPU는 폴링을 실행해야 하므로 비효율정이다.
폴링 ⇒ 하나의 장치(또는 프로그램)가 충돌 회피 또는 동기화 처리 등을 목적으로 다른 장치(또는 프로그램)의 상태를 주기적으로 검사하여 일정한 조건을 만족할 때 송수신 등의 자료처리를 하는 방식
동기 제어 ** → 송신 측과 수신 측을 일치 시키도록 제어 / 흐름 제어 → 버퍼 초과 방지 ( 버퍼 : 데이터를 한 곳에서 다른 한 곳으로 전송하는 동안 일시적으로 그 데이터를 보관하는 메모리의 영역 ) / 응답 제어 → 응답용 확인 메시지 전송 (3Way handshake방식)