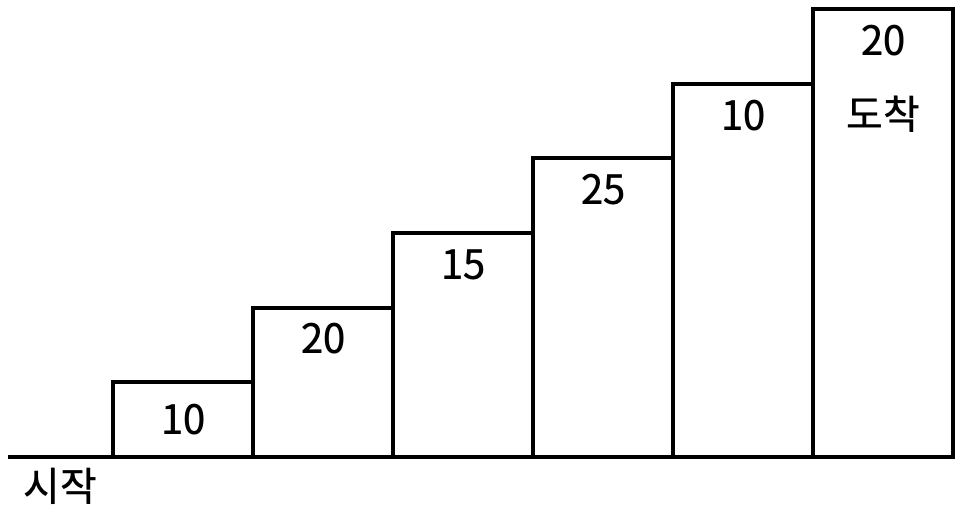
효주는 포도주 시식회에 갔다. 그 곳에 갔더니, 테이블 위에 다양한 포도주가 들어있는 포도주 잔이 일렬로 놓여 있었다. 효주는 포도주 시식을 하려고 하는데, 여기에는 다음과 같은 두 가지 규칙이 있다.
포도주 잔을 선택하면 그 잔에 들어있는 포도주는 모두 마셔야 하고, 마신 후에는 원래 위치에 다시 놓아야 한다.
연속으로 놓여 있는 3잔을 모두 마실 수는 없다.
효주는 될 수 있는 대로 많은 양의 포도주를 맛보기 위해서 어떤 포도주 잔을 선택해야 할지 고민하고 있다. 1부터 n까지의 번호가 붙어 있는 n개의 포도주 잔이 순서대로 테이블 위에 놓여 있고, 각 포도주 잔에 들어있는 포도주의 양이 주어졌을 때, 효주를 도와 가장 많은 양의 포도주를 마실 수 있도록 하는 프로그램을 작성하시오.
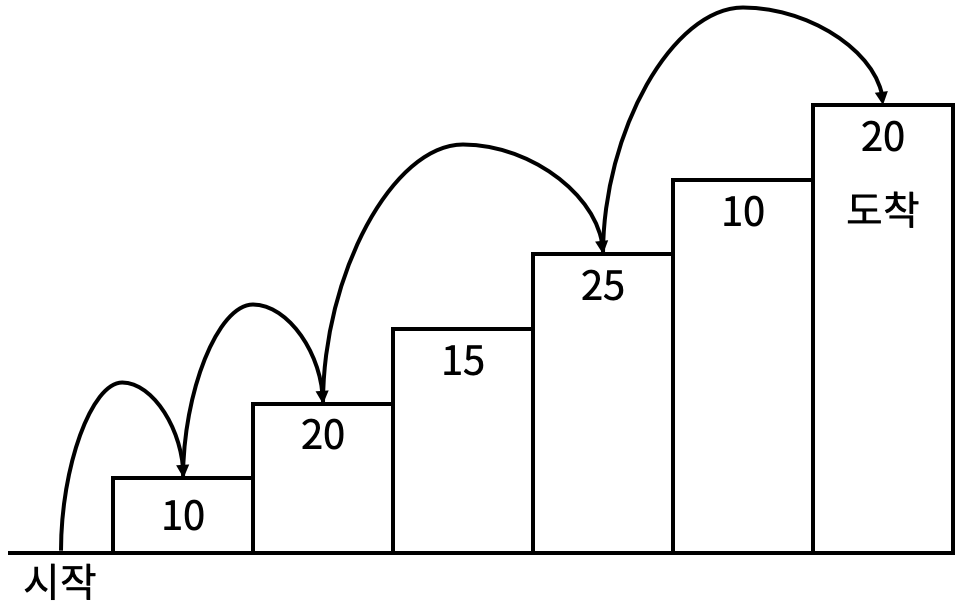
예를 들어 6개의 포도주 잔이 있고, 각각의 잔에 순서대로 6, 10, 13, 9, 8, 1 만큼의 포도주가 들어 있을 때, 첫 번째, 두 번째, 네 번째, 다섯 번째 포도주 잔을 선택하면 총 포도주 양이 33으로 최대로 마실 수 있다.
입력
첫째 줄에 포도주 잔의 개수 n이 주어진다. (1 ≤ n ≤ 10,000) 둘째 줄부터 n+1번째 줄까지 포도주 잔에 들어있는 포도주의 양이 순서대로 주어진다. 포도주의 양은 1,000 이하의 음이 아닌 정수이다.
출력
첫째 줄에 최대로 마실 수 있는 포도주의 양을 출력한다.
예제 입력 1복사
6
6
10
13
9
8
1
예제 출력 1복사
33
풀이
해당 문제는 다이나믹 프로그래밍으로 풀이하는 문제이다.
가장 신경써야 할 문제는 마실 수 있는 최대의 포도주의 양을 구하는것이기 때문에
비교를 해야한다.
총 3잔의 포도주가 주어졌을때
1,2 와 2,3 을 마셨을때의 값을 비교해야한다는것이다.
일단 문제에서 주어진것은 6잔의 포도주와 양이 주어졌고 최대의 포도주 양이 주어졌다.
일단 그것들을 토대로 문제를 그려보면 된다.
일단 6잔이 주어졌을때, 공통적으로 못마시는 잔의 수는 2잔이다.
이것을 단순 O 와 X 로 표기해 보았을때
3잔씩 체크를 한다고 치면 OOX, OXO, XOO 가 될 수 있다는 것이다.
따라서 단순히 저 세개의 경우의 수 중 가장 큰 값을 골라서 배열에 넣어주면 된다.
dp[1] 이라면 첫번쨰 와인인 6
dp[2] 이라면 두번째 와인과 첫번째 와인인 16
dp[3] 이라면 Math.max(첫와인+두번째와인, 두번째와인+세번째와인, 첫번째와인+세번째와인) 이 된다.
마찬가지로 더 구해본다면
dp[4] 일때는 첫와인+두번째와인+ 네번째와인 혹은 첫와인+세번째와인+ 네번째와인 이 될 수 있고
dp[5]일때는 첫와인+두번째와인+네번째와인+다섯번째 혹은 첫와인+세번째+네번째 혹은 두번째+세번째+다섯번째 등등 여러 결과가 나올것이다.
이것을 식으로 표기해보았을때
dp[1] = wine[1]
dp[2] = wine[1]+wine[2]
dp[3] = dp[3-1] 혹은 dp[3-2]+wine[3] 혹은 dp[3-3]+wine[2]+wine[3]
dp[4] = dp[4-2]+wine[4] 혹은 dp[4-3]+wine[3]+wine[4]
dp[5] = dp[5-3]+wine[4]+wine[5]
이런식으로 표현이 가능하다.
여기서 공통적으로 나오는 로직이 있다.
dp[i] = dp[i-1] 혹은 dp[i-2]+wine[i] 혹은 dp[i-3]+wine[i-1]+wine[i]
가 공통적으로 등장하게 된다.
단순히 이걸 코드로 풀이하면 된다.
package baekjoon.a2156;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class a2156 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(br.readLine());
int[] dp = new int[N+1];
int[] wine = new int[N+1];
for(int i=1; i<=N; i++){
wine[i] = Integer.parseInt(br.readLine());
}
dp[0]=0;
for(int i=1; i<=N;i++){
if(i ==1){
dp[i]=wine[i];
}else if(i==2){
dp[i]=wine[i]+wine[i-1];
}else{
dp[i]= Math.max(dp[i-1],Math.max(dp[i-2]+wine[i],dp[i-3]+wine[i]+wine[i-1]));
}
}
System.out.println(dp[N]);
}
}
입력 크기가 작은 부분 문제들을 해결한 후 메모이제이션 기법을 사용해서 (미리 결괏값을 저장하여) 문제를 푸는 것
상향직 접근법 → 해당 문제를 풀기 위해 가장 단순한 형태의 해답을 구한 후 이를 저장 후 해당 결괏값을 가지고 상위 문제를 풀이
메모이제이션 : 프로그램 실행 시 이전에 계산한 값을 저장하여, 다시 계산하지 않도록 하여 전체 실행 속도를 빠르게 하는 기술
분할 정복
큰 문제를 풀기 위해 문제를 잘게 쪼개서 풀이한 후 다시 합병하여 문제의 답을 얻는 알고리즘
하향식 접근법 → 상위의 해답을 구하기 위해 하위의 해답을 구하는 방식
일반적으로 재귀함수로 구현한다.
공통점과 차이점
공통점
문제를 잘게 쪼개서, 가장 작은 단위로 분할한다
차이점
동적 계획법
메모이제이션 기법 사용
상위 문제 해결시 재활용함
분할 정복
부분 문제는 서로 중복되지 않는다.
메모이제이션 기법을 사용하지 않음
동적 계획법 활용하기
기존의 재귀함수를 호출할 땐?
팩토리얼을 구현할 때, 각각의 매개값의 결과를 구하기 위해 매번 다시 처음부터 순회하며 값을 구한 후 더해준다.
동적계획법을 이용한다면, 이미 계산한 값들은 저장해놓고 순서를 넘기기 때문에 불필요한 호출을 하지 않는다.
public static int recur(int n){
if(n<=1){
return n;
}
return recur(n-1)+recur(n-2);
} //기존의 재귀함수 호출
public static int dynamicFunc(int n){
Integer[] cache = new Integer[n+1] //저장용 배열을 생성한다.
cache[0] = 0; //미리 구할 수 있는 값들은 저장해놓는다.
cache[1] = 1;
for(int i=2; i<n+1; i++){
cache[i] = cache[i-1]+ cache[i-2]; //계산된 값을 저장해가며 올라간다.
}
return cache[n];
}
}
분할 정복을 사용하는 병합 정렬과 퀵 정렬
병합 정렬
재귀 용법을 활용한 정렬 알고리즘
리스트를 절반으로 나눠 비슷한 크기의 두 리스트로 나눈다.
각 리스트를 재귀적으로 합병 정렬을 이용해 정렬한다.
두 리스트를 다시 하나의 정렬된 리스트로 병합한다.
리스트를 더 이상 쪼갤 수 없을 때까지 나눠서 정렬을 하며 다시 합친다.
병합 정렬은 크게 두 가지의 단계를 거친다.
끝없이 분할하는 split 단계
분할한 것들을 병합하는 merge단계
병합 시에 매번 각각의 데이터의 최소값의 인덱스를 저장한다.
병합시에 각각의 데이터를 비교해서 작은 것을 앞에, 큰 것을 뒤에 놓게 된다.
각각의 데이터는 매번 병합 시에 정렬이 되어있는 상태이다.
항상 데이터가 들어오면 두 단계로 분리한다.
분리한 데이터를 단계별로 합친다.
합칠 시에는 데이터를 비교해가면서 병합된 데이터는 정렬이 된 상태를 유지하게 한다.
분할 메서드를 선언해 보자.
public static void split(ArrayList<Integer> list){
if(list.size()<=1){
return;
}
int medium = list.size()/2;
List<Integer> leftList = new ArrayList<>(list.subList(0,medium));
List<Integer> rightList = new ArrayList<>(list.subList(medium,list.size()));
System.out.println(leftList);
System.out.println(rightList);
}
subList() 메서드를 사용하여 사이즈 /2 만큼의 리스트를 두개 생성한다.
해당 메소드를 재귀호출하여 나눈 후 병합한다.
public static ArrayList<Integer> mergeSplitFunc(ArrayList<Integer> list){
if(list.size()<=1){
return list;
}
else{
int medium = list.size()/2;
//재귀 호출로 더 이상 나눌 수 없을때까지 나눈다.
ArrayList<Integer> leftList = mergeSplitFunc(new ArrayList<>(list.subList(0,medium)));
ArrayList<Integer> rightList = mergeSplitFunc(new ArrayList<>(list.subList(medium,list.size())));
return mergeFunc(leftList,rightList);
}
} //나누는 부분에서 재귀호출을 실행한다.
그리고 병합 메소드를 선언한다.
더 이상 쪼갤 수 없을 때까지 분할 후 차례로 들어오는 것이기 때문에 왼쪽 리스트, 오른쪽 리스트 이렇게 값을 비교한다.
반복문이 아닌 while 문으로 포인터에 1씩 더해주면서 값을 비교하고 종료시킨다.
3개의 케이스를 만들어서 케이스별로 정렬을 시도한다.
왼쪽 리스트와 오른쪽 리스트가 존재할 때, 왼쪽 리스트만 존재할때, 오른쪽 리스트만 존재할 때를 비교한다.
각각 리스트별로 다른 사이즈가 될 수 있기 때문이다.
public static ArrayList<Integer> mergeFunc(ArrayList<Integer> leftList,ArrayList<Integer> rightList){
ArrayList<Integer> mergedList = new ArrayList<>();
int leftPoint = 0;
int rightPoint = 0;
//CASE1 : left / right 둘 다 존재할 때
while(leftList.size() > leftPoint && rightList.size()>rightPoint){
if(leftList.get(leftPoint)> rightList.get(rightPoint)){
mergedList.add(rightList.get(rightPoint));
rightPoint++;
}
else{
mergedList.add(leftList.get(leftPoint));
leftPoint++;
}
}
//CASE2 : right 데이터가 없을 때
while(leftList.size()>leftPoint){
mergedList.add(leftList.get(leftPoint));
leftPoint++;
//나머지를 다 넣어준다.
}
// 왼쪽 데이터가 처리된 상태이지만 오른쪽 데이터가 아직 존재하는 상태라면
// case3으로 들어올 수가 있다.
//CASE3 : left 데이터가 없을 때
while(rightList.size()>rightPoint){
mergedList.add((rightList.get(rightPoint)));
rightPoint++;
}
return mergedList;
}
퀵정렬
퀵정렬이란?
정렬 알고리즘의 꽃이라고 할 수 있다.
속도도 빠르고 코드도 간결하게 쉽게 정렬이 가능하다.
피벗(기준점)을 정해서, 각각의 데이터를 확인하면서 피벗보다 작은 데이터는 왼쪽, 큰 데이터는 오른쪽으로 배치한다. ****(위치를 잡는다고 생각하면 좋다. 보통 맨 앞에 있는 값을 피벗으로 정한다.)
각 왼쪽 오른쪽의 데이터들은 재귀용법을 사용해서 위 작업을 반복한다.
함수는 각각 왼쪽 + 피벗 + 오른쪽을 리턴한다.
피벗을 정한 후 데이터를 순회하면서 피벗을 기준으로 양쪽에 데이터를 배치한다.
병합 정렬과 차이점은 병합정렬은 분리 후 정렬, 병합 과정을 거친다면 퀵 소트는 분리 시에 정렬하며 나중에 합친다.
코드로 구현해 보기
기본적인 split 함수 구현해 보기
재귀함수를 선언한다.
매개값으로 주어지는 배열의 사이즈가 1이라면 아무 동작도 하지 않은 채 배열을 리턴한다.
사이즈가 1 이상이라면 맨 앞의 데이터를 기준점으로 잡고 왼쪽에 배치할 배열과 오른쪽에 배치할 배열을 생성해 인덱스 1부터 순회하여 값이 작다면 왼쪽, 크다면 오른쪽배열로 데이터를 넣어준다.
순회가 끝난 후 각 배열의 데이터를 담을 mergedArr를 생성해 addAll 메서드로 데이터들을 넣어준다.
이때 재귀함수를 호출한다.
왼쪽데이터를 또다시 split 함수로 나눠서 정렬하고, 오른쪽 데이터 또한 마찬가지로 split 함수로 나눠서 정렬한다.
따라서 addAll 메서드 안에 split 함수를 호출하도록 한다.
기준점 (피벗)은 단건만 add 메서드를 통해 삽입한다.
public static ArrayList<Integer> splitFunc(ArrayList<Integer> dataList) {
if (dataList.size() <= 1) {
return dataList;
}
int pivot = dataList.get(0);
ArrayList<Integer> leftArr = new ArrayList<>();
ArrayList<Integer> rightArr = new ArrayList<>();
for (int i = 1; i < dataList.size(); i++) {
if (dataList.get(i) > pivot) {
rightArr.add(dataList.get(i));
} else {
leftArr.add(dataList.get(i));
}
}
ArrayList<Integer> mergedArr = new ArrayList<>();
mergedArr.addAll(splitFunc(leftArr));
mergedArr.add(pivot);
mergedArr.addAll(splitFunc(rightArr));
return mergedArr;
}
내림차순으로 정렬하고 싶다면 반대로 동작하도록 하면 된다.
퀵 정렬의 시간복잡도
병합정렬과 유사하다. 시간복잡도는 O(n logn) 이 된다.
최악의 경우에는 이미 정렬된 배열에서 pivot 이 가장 크거나 , 가장 작으면 가장 큰 시간이 소요된다.
모든 데이터를 비교해야 하는 상황이 나올 수 있으므로 O(n^2)가 된다.
1,2,3,4,5의 데이터를 퀵 정렬로 정렬한다면, 1 2345 2 345 3 45 이런 식으로 정렬하기 때문에 비효율적이다.
마무리
병합정렬과 퀵 정렬은 어떻게 봤을 때 비슷해 보입니다.
병합 정렬은 더 이상 쪼갤 수 없을 때까지 쪼갠 후 정렬하며 병합한다면, 퀵 정렬은 쪼개면서 정렬을 하고 합치는 느낌입니다.
검색을 해보니 Collections의 sort는 병합정렬을 기반으로 한 팀 정렬 방식을 사용하고, Arrays의 sort는 듀얼피벗 퀵정렬 방식으로 정렬한다고 합니다.
정렬 방법에 대해서 공부하면서 자바에서 어떠한 api 가 어떤 알고리즘을 구현해 제공해주는지 알고 각각 맞는 상황에 사용하는 게 관건인 것 같습니다 :D